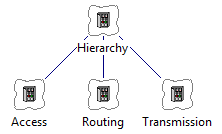
 The lean collection type in STEM is long established as a neat way to group elements
and provide systematic aggregation across all results available for those elements.
A collection can also be used to group other collections, and so it is possible
to build up one or more hierarchies of the costs in a model (e.g., by network function,
or by vendor).
The lean collection type in STEM is long established as a neat way to group elements
and provide systematic aggregation across all results available for those elements.
A collection can also be used to group other collections, and so it is possible
to build up one or more hierarchies of the costs in a model (e.g., by network function,
or by vendor).
This is easy to manage in a modestly-sized model, but it becomes harder to verify
when a model is very large and extends over multiple views. To address this challenge,
we are working on a partition concept which requires
any nominated hierarchy to be checked for completeness, and to ensure that each
cost appears precisely once within that hierarchy. The Editor makes this a breeze
to work with by automatically breaking previous links when a cost (or group of costs)
is connected to a new branch of the hierarchy.
Navigating the results of a large model can also be challenging; even the filtering
option in STEM 7.5 won’t help if you don’t know what to look for in
the first place! A partition enables an optional top-down navigation of results
where you can expand individual branches of a hierarchy to drill-down into the desired
detail.
Mathematical definition and implementation in STEM
A partition of a set X is a set of nonempty subsets of X such that
every element x in X is in exactly one of these subsets (i.e., X
is a disjoint union of the subsets)1.
In STEM terms: a partition is a homogeneous collection
where all sub-collections and all elements of the given type appear exactly once.
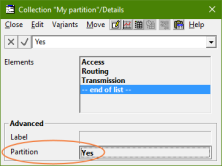 We have
added a new collection input, Partition = Yes / No, which activates the
required constraints. A key insight is that this property must be defined only for
the top-most collection in a hierarchy; this is sufficient to impose the constraints
on all the branches.
We have
added a new collection input, Partition = Yes / No, which activates the
required constraints. A key insight is that this property must be defined only for
the top-most collection in a hierarchy; this is sufficient to impose the constraints
on all the branches.
Just as with plain collections, it is quite feasible to have more than one partition
of any given type, and even for them to share one or more sub-collections.
Note: a regular collection makes no such checks and allows for the inclusion of
overlapping sub-collections. However, by design, STEM has always avoided double-counting
in such an instance, calculating the associated results as the aggregate over all
elements which appear in any of the sub-collections.
Working with an example
If we set the input Partition =
Yes for the collection, My partition,
in the illustration below, then its structure will be checked for completeness and
uniqueness whenever the model is run. Any relevant issues will be reported as warnings.
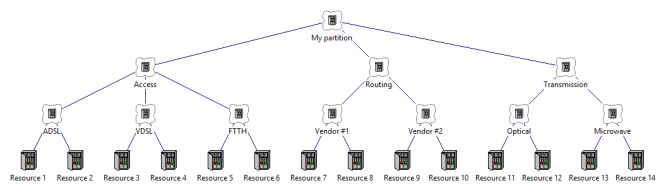
Figure 1: Example partition structure
However, there is much more that the Editor can do to manage the membership proactively,
e.g.:
- if I add Vendor #2 to
Access, then it will be removed from Routing
- if I add Routing to Vendor
#2, then the Editor will report the circularity and immediately undo the
change
- when I first set Partition =
Yes then the Editor will ensure that:
- any missing resources are added
- any existing duplicates are reported as they would be at check-time.
The Editor will not fix anything which would require an arbitrary choice to be made
and any issues of this sort will be left for you to resolve when the warnings are
reported later.
Using a partition to navigate available elements for results
 Once
you have a verified partition, it will obviously make a pleasing alternative to
the usual flat list of available elements to draw when accessing results:
Once
you have a verified partition, it will obviously make a pleasing alternative to
the usual flat list of available elements to draw when accessing results:
- it will facilitate a top-down discovery of the model structure
- it will make it easy to drill-down into the aspects of most interest (e.g., greatest
cost).
The operation of this hierarchical list remains to be specified in full, but it
will include the ability to expand or collapse the sub-collections within a partition
to any depth.
We are considering various element-navigation options as follows, perhaps selected
from a Navigation drop-down below the
Available list (for drawing graphs):
- Flat: all elements in the model, in logical or alphabetical
order
- By type: equivalent to a collection of flat partitions
of each type (same order)
- By partition: equivalent to a collection of all defined
partitions (alphabetical)
- Individual partition 1: just the named partition (which
could also be a single collection of partitions)
- Individual partition 2: …
There is nothing much yet to be gained from understanding these tentative options,
but please try to figure them out first if you want to make any further suggestions!
Controlling the order of elements in a collection (and the model too)
Historically, list management has not been a focus in STEM. However, it will become
a more significant expectation once navigation by partition is implemented and you
want to determine the order in which items are presented at each level.
So we are planning a minor change to the drag-and-drop behaviour for collections
as follows:
- when you first drop a selection of elements in a collection, they are added in the
order you see them (across, and then down)
- but if some are already present, currently they are not disturbed
- instead, we will move them to the end with the other new additions, as if we had
removed them first.
This will provide a very intuitive and accessible way to control the order of a
collection, and in turn each level of a partition hierarchy.
We may add rudimentary up/down commands to the Elements
list-box in the Details dialog to sort the elements
manually, but it will be fundamentally easier to visualise and then update the order
by manipulating the elements graphically in two dimensions first.
Logical order when selecting elements for a graph
The list of elements presented by the results program appears in the rather obscure
order of creation unless you select Alphabetical
order. The raw logical order is not very useful and more or less impossible to change.
In fact it would always have been very cumbersome to manipulate the master list
of elements of a given type in a large model.
Now we plan to add an option to re-order this list from a partition of the corresponding
type, proceeding through the elements depth-first, as per the fully-expanded hierarchical
navigation. The task will be much more manageable this way, as you can focus on
one branch at a time rather than manipulating the whole list at once, and it will
reap the same benefits of manipulating the elements graphically in two dimensions.
Other miscellaneous considerations
A prototype of this functionality has received rave reviews in recent demonstrations,
but there are many questions which remain to be resolved in such a broad implementation
before the system will be ready and sufficiently tested for external consumption.
Some of the more interesting details are presented in the following paragraphs.
It is quite feasible for a collection to have both sub-collections and explicit
elements as members, and where this is the case:
- we may optionally group the explicit elements in an automatic
Other category
- there is a related suggestion to be able to graph the top n items of a given
category, with the remainder grouped together as Other.
An existing function or market segment may be included within a partition of resources
or services, respectively, just as if it were a regular collection of those elements.
It may prove useful as an option to indicate how many leaves there are within a
given branch of a hierarchy, and/or for the individual leaves to be numbered. This
would make it easy to verify that you have a complete report at any level, especially
if linked to Excel.
A partition will still work with template replication:
- any partition item which is replicated, either an element or a collection of replicated
elements, will be replaced by a collection of each variant instance, so the partition
will just branch by variant at this level, but
- it will be an error for a partition to include a replicated collection which includes
a non-replicated element as this latter element would then be present in each variant-instance
collection, making the structure as a whole non-disjoint.
If a template has many variants, they can already be grouped with collections, and
now this would allow for them to be arranged in a partition too. This would provide
for a hierarchical navigation when drawing a graph for the
Variants tab too, with potentially interesting implications for
Linear Selection mode, and even more so for Linear
Selection mode with cost-breakdown results – see
separate article.
Better browsing, easier consistency checks
Results browsing will be significantly enhanced by the ability to navigate both
elements and variants via a top-down hierarchy defined by one or more partitions
in a model. This will deliver benefits for both the original modeller and someone
else less familiar with it:
- guiding the exploration and comparison of related results at every level, and
- enabling an orderly and informed discovery/digestion of what is in the model.
1 See
https://en.wikipedia.org/wiki/Partition_of_a_set.