STEM comes with comprehensive documentation and online help on the functionality of the software. However, the art of modelling is hard to prescribe and is typically learned first-hand from a training workshop through examples, and then gradually developed with experience.
 This
informal blueprint is aimed at the infrequent or peripheral user just starting to
get curious about modelling and is an attempt to stimulate individual creativity
by providing guidance on how to model typical network contexts and how to think
about the overall scope of a model.
This
informal blueprint is aimed at the infrequent or peripheral user just starting to
get curious about modelling and is an attempt to stimulate individual creativity
by providing guidance on how to model typical network contexts and how to think
about the overall scope of a model.
Where to start?
We begin with the general question: how much detail? It is usually best to start
with something simple and expand from there, as this develops understanding of the
dynamics before key results become obscured by the non-linear complexities of a
detailed model.
What’s the objective?
Before there is any point considering the shape of the model, first some objective
must be defined. What questions might the model answer? What scenarios could it
help compare? This should define some immediate requirements for what kind of results
the model should generate… but since STEM automatically generates all results (ignoring
pure cost or pure revenue models), what may be more pertinent is to ask what data
you can start from as inputs, and specifically what level of granularity is available.
If the data doesn’t fit, then the validity of the entire model will be predicated
on the ability to map the real data onto the input categories defined in the model.
What are the elements?
Ultimately, a model is characterised by the different services and resources modelled,
but this is slightly to miss the wood for the trees. The key question is what specifically
distinguishes different groups of services: is it ARPU, is it technical requirements?
The same is true on the cost side: don’t start with an equipment inventory, but
ask what sources of cost are dimensioned or located together, or have common financial
lifetimes.
How does the network stack up?
Or in other words, what are the main technical drivers and dependencies? This is
where you determine the functional layers of the network: is it just access, switching
and transmission, or are there multiple levels of aggregation and consolidation?
Whereas the primary access is likely dimensioned on connections (or perhaps concurrent
circuits or bandwidth in mobile) what rules (BH consolidation and contention) govern
the effective loading on other parts of the network?
What other dimensions are there besides connections, traffic and location: do you
need to model the switching layer in terms of busy-hour call attempts?
Aggregation is easy, but should the model disaggregate between different destinations
(domestic/international, on-net/off-net), and if so, is that information encoded
in the originating services, or are the respective shares estimated later?
Structuring data
Are you going to link any of the inputs from Excel? If so, you may avoid a lot of
pain later by making this decision early on before you commit too much data to dialogs
in STEM.
Do you need to combine multiple currencies? Again, you will save time re-building
later if you link nominal prices from User Data from the start.
Who is the audience for this model? Are they interested in the structure in STEM
or simply the outputs? If the latter, then we strongly recommend use of the STEM
add-in for Excel to create a combined input/results interface which allows the executive
to focus on the business performance.
A more fundamental question is when to use STEM versus Excel. There is no absolute
answer, but we suggest that any model requiring detailed lifetime modelling of multiple
infrastructure assets, or requiring structural replication over multiple geographies
or market segments, will benefit from the integrated calculations, consistency and
automation which STEM offers.
High-level specification
When Implied Logic runs a modelling workshop as part of a STEM training course, our consultants
are expected to work through these kinds of questions with the client team in order
to get a common understanding of objectives and issues before concentrating on the
detail of the model. The standard brief is to co-develop a short presentation of
perhaps five slides which answers these questions and constitutes a high-level specification
for the model. This provides a vital reference against which to measure the effectiveness
of the model, as well as a flying start for documenting the completed model later.
Mobile
We have a standard GSM-UMTS framework model which has been used in many
client situations. The approach it takes is readily summarised as follows:
- distinguish between different revenue classes (business and residential) and different
types of service (voice/data, different tariffs)
- add up the different bandwidth implications of different services
- disaggregate traffic between different geo-types to capture cost differential between
urban and rural areas
- use Locations to capture the roll-out dimension for each separate geo-type
- model backhaul per base-station site with some averaging assumption.
Template replication could be used for the geo-types, but with only four in the
present model, this is hardly worth the effort. It would also be possible to extend
the detail by modelling demand from geo-types up, e.g. to capture some kind of tendency
to call people in the same geo-type.
An interesting challenge would be to replicate individual base-station sites, with
specific backhaul cost data and so on; but this would have onerous requirements
for input data.
Data services and STEM 7.0
Over time, different people have developed different approaches for modelling data
services, but we hope that the approach we have adopted for STEM 7.0 is broadly
in line with all of these, and moreover, that 6.2 models can be structured now such
that the subsequent transition to STEM 7.0 will be natural and straightforward for
new and experienced users alike.
Volume-driven or peak-driven?
In modelling terms, the key distinction between a voice service and a data service
is that, while the former is typically sized primarily in terms of traffic volume
(annual minutes), from which familiar parameters are used to calculate BH traffic,
in contrast, a data service is more likely characterised in terms of a nominal peak
bandwidth, plus a variety of parameters describing contention, duty cycle, burstiness
and so on.
The standard ‘trick’ for shoe-horning the description of a data service into STEM’s
classic voice-centric format, has four elements:
- to define the various data parameters in User Data
- to calculate the effective BH traffic
- to calculate the total traffic volume (per user) using the inverse of the familiar
parameters which calculate voice BH traffic from annual volume
- to link Annual Traffic per Connection input to these calculations, so that the BH
traffic is then effectively the number you first thought of!
A common formalism
One of the strengths of modelling in STEM is the consistency which is encouraged –
if not enforced – by the combination of built-in algorithms and data structures.
Therefore, for STEM 7.0 we have adopted the simplest possible approach which adds
two new inputs to describe the data bandwidth, plus an explicit option to select
the direction of calculation.
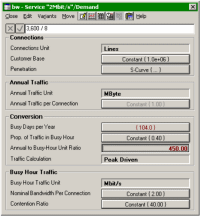
- Nominal
Bandwidth per Connection
- Contention Ratio
- Traffic Calculation
= Volume Driven or Peak Driven
If the user selects Peak Driven, then:
and the traffic volume, e.g. Megabytes down-loaded in a year, becomes a calculated
quantity rather than an input.
The contention ratio is a measure of contention in the busy hour, rather than an
average over the day, so we still need PropTiBH and BDpYr to calculate:
- AT = Connx . BDpYr . UR . NBpC / CR / PropTiBH
One open question you might consider is whether an extra parameter is required to
capture the variance between BHT = Connx . NBpC / CR used for dimensioning purposes,
and the average required for volume calculations, which I suspect is not quite the
same.
In a typical network model, the Contention Ratio defined within the Service might
describe contention in a primary network interface, and additional ratios may be
factored in to capture aggregation effects onto the core network.
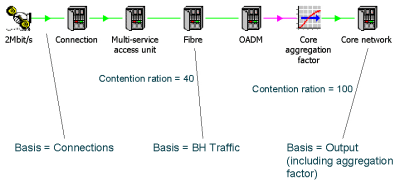
Contention onto the core network
Geography and template replication
Prior to the introduction of template replication, geography was a real no-no in
STEM, beyond the macro approach of Locations. Now it is feasible (within reason)
to model individual switch sites or links on a network, so long as you have the
data to match. As per the introductory remarks, don’t leap into the deep end. Start
with a macro model, and then add just a couple of variants to make sure your model
behaves as expected, before implementing the full detail.
Exchange sites
The easier example is modelling originating traffic and equipment for individual
exchange areas. You can replicate a market segmentation and services for each exchange,
and then aggregate core traffic (non-replicated) for the whole network. Within a
template, you might still use a Location, e.g. to dimension the scope of the access
network. The core aggregation relies on the fact that you can drive a non-replicated
Resource from replicated exchange elements; in other words using the non-replicated
Resource as a bucket to collect traffic from each exchange.
Nodes and links
A simplistic approach to the dimensioning of individual links just assumes some
proportion of network total per link, but a thorough ‘scientific’ approach requires
you to get into intricate detail, specifying individual services per theoretical
route, and then fabricating ‘matrices of Transformations’ in order to map each route
onto individual nodes and links. This technique was used to create a voice LRIC
model for Telkom Indonesia – see the previous newslettter article
LRIC analysis of a voice backbone network.
However you decide to proceed, there is one gotcha which you must understand, namely
that a replicated Resource cannot be directly driven by a non-replicated Service.
Instead, you need to include a number of Multiplier Transformations in the Template
with the Resource, one for each Service which might drive it, so that these multipliers
can be set up as Template parameters in order to fulfil the required mappings per
replicated Resource.
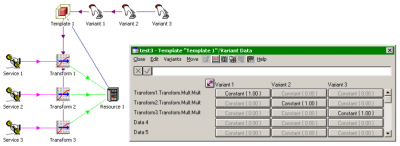
A replicated Resource cannot be directly driven by a non-replicated Service
Overheads
We usually expect to model non-network costs, such as customer-acquisition, network
maintenance, call centres and so on. These are usually driven off total subscribers
or total traffic to ensure thorough cost allocation. The overall magnitude may be
readily benchmarked, but the underlying driver may not be obvious. During the last
User Group there was a presentation, Approaches to modelling opex,
which covered some typical opex items and overhead costs, and this would be useful
background reading.