 Cloud services have burst onto the IT scene in a big way as virtualisation technology
has come of age and next generation broadband networks now have the power to take the office to the business. It is
these factors which realise the potential economy of scale of many separate companies
sharing capacity in a uniformly managed and highly utilised data-centre environment.
Cloud services have burst onto the IT scene in a big way as virtualisation technology
has come of age and next generation broadband networks now have the power to take the office to the business. It is
these factors which realise the potential economy of scale of many separate companies
sharing capacity in a uniformly managed and highly utilised data-centre environment.
An interactive workshop across two sessions at the recent
STEM User Group Meeting in Cambridge UK examined the business model for
providing email as a cloud service. The exercise also aimed to determine at
what scale it makes economic sense for an individual company to run its own email
infrastructure (ignoring factors such as technical competence or data-protection
governance).
1. Studying both sides of the equation in detail
After an initial introduction to the topic, the audience split into two teams with
the following objectives:
-
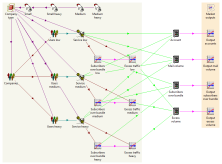 for the Market track (A), led by Robin BAILEY,
to create a model of the market for such email services based on some given assumptions
about the numbers of businesses of varying sizes in a national market, and varying
user profiles (by email usage) within those organisations, together with some group
estimate of what would be an attractive price for the service
for the Market track (A), led by Robin BAILEY,
to create a model of the market for such email services based on some given assumptions
about the numbers of businesses of varying sizes in a national market, and varying
user profiles (by email usage) within those organisations, together with some group
estimate of what would be an attractive price for the service
-
 for the Technical track (B), led by Frank HAUPT,
to model a generic infrastructure for providing email as a service, including email
server (licences), storage (including backup and archive), and technical staff,
together with associated cost assumptions.
for the Technical track (B), led by Frank HAUPT,
to model a generic infrastructure for providing email as a service, including email
server (licences), storage (including backup and archive), and technical staff,
together with associated cost assumptions.
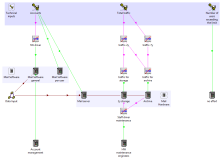
2. Modelling a value chain in STEM
Having carefully agreed for Team
B to work from the same drivers as would be available as the outputs
from Team A, the two separate models were easily
combined (in the follow-up session on day two) into a detailed business model for
the cloud email provider which could be readily calibrated for any specific territory.
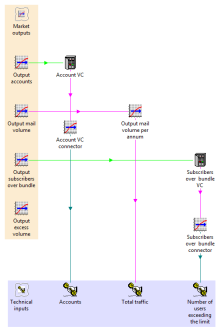 The value-chain concept in STEM makes it easy to identify the email commodity (cost)
in the market model with demand for the service in the technical model. The
subscription revenues in the latter show up as equivalent operating costs in the
former.
The value-chain concept in STEM makes it easy to identify the email commodity (cost)
in the market model with demand for the service in the technical model. The
subscription revenues in the latter show up as equivalent operating costs in the
former.
Injecting a degree of gritty reality into the proceedings, and proving that this
really was a live event, a slight ambiguity emerged in the agreed interface between
the models:
-
Team A used an assumption about the number of accounts exceeding a maximum
traffic limit (e.g., 1GB p.a.) to calculate an actual volume (in MB) over bundle,
expecting that traffic over bundle would be charged on this basis; whereas
-
Team B expected the driver to be simply the number of accounts over bundle
which would incur a fixed second-bundle fee.
Such misunderstandings are commonplace and almost inevitable between disparate teams.
Fortunately the discrepancy was immediately apparent when the models were connected.
It was easy to fix as the market model actually calculated the number of accounts
over bundle as its first step towards calculating the resulting volume.
Note: if only such mismatches were more readily apparent when
connecting Excel models!
The final results were only indicative as the model was assembled from two fragments
built in little more than 40 minutes each in a workshop situation! Nevertheless
it was clear that there was more than enough margin to make this a very viable business.
3. The DIY scenario
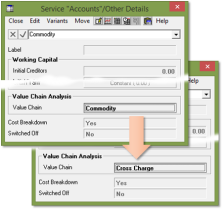 It was then a simple adaptation to ‘remove the middle man’ and model
the scenario of just one company investing in its own infrastructure (accepting
of course that the cost structure would be very different between the two different
approaches). The resultant (lower than expected) cost per user showed us that
our initial tariff for the cloud provider was too high.
It was then a simple adaptation to ‘remove the middle man’ and model
the scenario of just one company investing in its own infrastructure (accepting
of course that the cost structure would be very different between the two different
approaches). The resultant (lower than expected) cost per user showed us that
our initial tariff for the cloud provider was too high.
However, even with this assumption altered in the original model to half of the
standalone cost per user, there was still a very healthy margin for the cloud provider.
So the exercise proved beyond any doubt the original hypothesis that there is a
massive efficiency to be gained by migrating towards the shared capacity of such
cloud services.
4. 21st century economies of scale
With more time, the next logical step would have been to exclude those portions
of the market for whom the cloud solution would be uneconomic (perhaps larger companies
with lots of heavy users) to see how this impacted the business case for the provider.
Considering that, by definition, such companies would be making the most efficient
use of the infrastructure, it follows that they might be the least profitable segment
and, as such, one that the cloud provider would be happy not to serve.
Naturally the STEM business-modelling software for industry
calculates the per-segment efficiency and profitability ‘out of the
box’, as well as the overall profitability and headline NPV results.
In due course we may develop the workshop model into a more rounded example model
which we could publish online for you to interact with directly.
For now you can read more about this exercise in the proceedings of the
STEM User Group Meeting which may be downloaded from the panel to the
immediate right of this article. (A one-time registration is required.)