STEM’s template replication feature facilitates the generation of very large, repetitive
model structures, where a similar demand or costing methodology must be reproduced
consistently for different sites on a network. Key parameters, such as numbers of
subscribers or average traffic requirements, are automatically plugged into otherwise
identical copies of a common template structure, guaranteeing consistency and vastly
simplifying future maintenance of the model.
This technical article uses a cut-down network configuration to illustrate how this
technique can be extended to model a two-tier aggregation architecture.
Managing very large, repetitive model structures
Consider the provision of broadband over DSL: each subscriber requires connection
to a port on a DSLAM, and sufficient backhaul capacity must be provided for the
expected busy-hour traffic load. A simple STEM model captures the costs of the DSL
cards and chassis, plus the cost of a suitably dimensioned leased line, based on
subscriber and traffic forecasts for three classes of user.
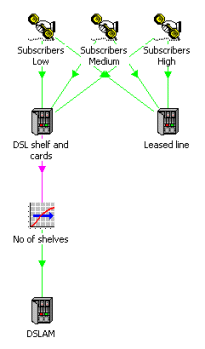
Basic network elements dimensioned according to connections and bandwidth
Aggregating this approach over multiple sites requires more than just increasing
the basic subscriber numbers. Attention must be paid to the differing levels of
slack capacity in the DSLAM at each site, and on the selection of leased-line capacity
at the site level. So the existing model elements for a site are linked as a Template,
and can then be automatically reproduced for a number of related Variant elements.
The numbers of subscribers for each class of user are identified as parameters for
the site Template, and then the respective data per-site are entered in the Template
Variant Data table.
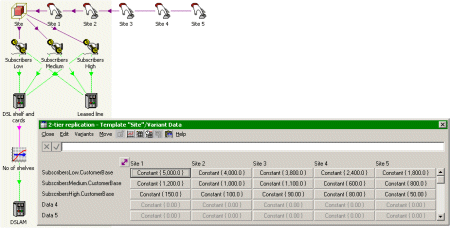
Site template and variant data for subscriber numbers
Whenever the model is run, STEM automatically generates a separate copy of the Site
template for each site-location Variant, and performs the DSLAM and backhaul calculations
separately for each site.
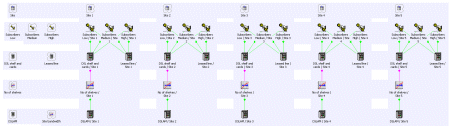
Expanded model showing separate cost model for each site
This means that you can explore the full range of technical and financial outputs,
both at the individual site level, and correctly aggregated for the network as a
whole.
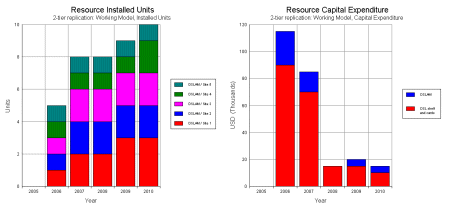
DSLAM numbers for individual sites and total capex for all sites
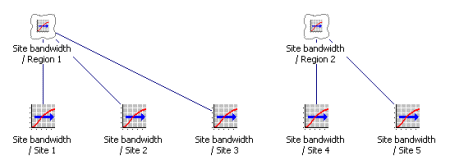
Aggregating bandwidth by region
Local points of presence are typically grouped together by region, both for reporting
purposes, and also for bandwidth aggregation onto a core network. If you just need
port numbers or capex spend, broken down by region, then all you need to do is link
relevant Variants as a Collection. This single, structural link, enables STEM to
calculate regional totals of all the existing per-site results, effectively as sub-sets
of the network totals.
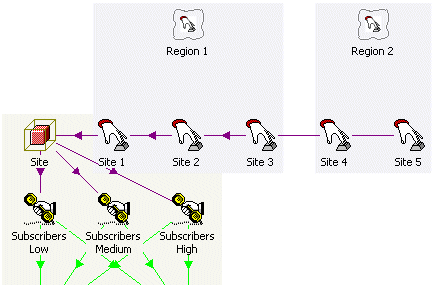
Using Collections to aggregate sites by region
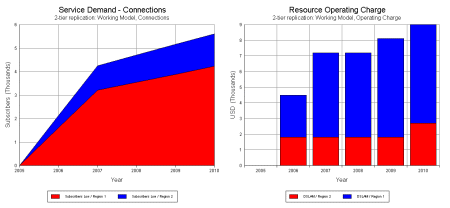
Regional totals for subscribers and operating charge
The Collection concept works as an element-grouping mechanism for existing results,
but cannot be used to drive other elements in a model. If you want to add a dimensioning
calculation based on regional bandwidth totals, then you need to add a device to
the site Template to map the bandwidth requirements of a site onto an ‘aggregator’
Resource for the appropriate region. This aggregator Resource effectively sums the
used capacity of each of the leased lines coming into the regional hub.
One way to achieve this is to add a ‘region number’ as a parameter for the site
template; this functions as an index identifying the appropriate region for a given
site, 1.0 for Region 1, 2.0 for Region 2, and so on.
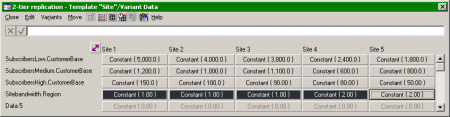
Region number as variant data for the site template
This parameter governs one of the user data for a Transformation called ‘Site bandwidth’,
which picks up used capacity for the leased line. Select Requirements from the Transformation
icon menu to display the Requirements dialog, and then click the (expand) button
to reveal the individual mappings.
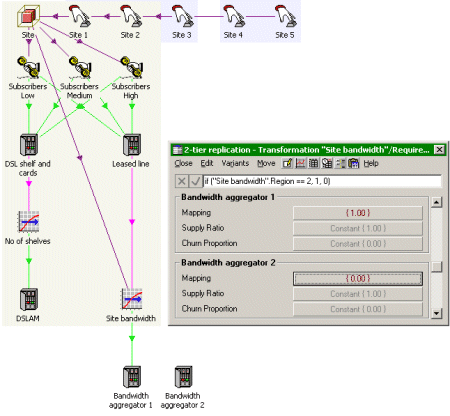
Using formulae to control mappings for Resource Requirements per individual site
For the Mapping associated with the Transformation’s Requirement for Aggregator
n, you can then use the formula if(Region = = n,
1, 0), so that the bandwidth for each site is only mapped on to the relevant
aggregator for a given region.
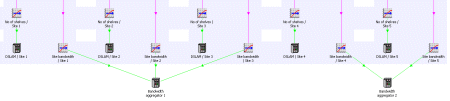
Expanded model showing discrete mappings
Note: the expanded model will already contain a Collection linking all the relevant
Transformations for a given region, which is generated automatically in order to
support the regional aggregation of results. However, at the time of writing, a
Collection cannot be used to drive other elements in a model, even if its existence
could be anticipated!
Automatically generated collections
Mapping aggregate bandwidth into a regional template
So far, we have mapped specific site variants onto the relevant regional aggregator.
This aggregator is a Resource, which could be used as a simple cost model for the
regional hub. More likely you would want to model the hub in more detail and, for
the same reasons as the site, ideally using another template.
However, variant data can only be defined as time-series, and cannot include references
to other elements; so it is not possible (at the time of writing) to link an individual
hub template directly to the appropriate regional aggregator. Instead, the hub template
must include one transformation for each region, where the transformation multiplier
can be checked against a region index (inherited from the hub variant data) in order
to define an ‘identity matrix’ between the regional aggregators and the copies of
the hub template. More specifically, the first of these ‘collector’ transformations
defines the region number in User Data (as a template parameter), and then the multiplier
for the nth collector is defined with the formula if("Collector
1".Region = = n, 1, 0). When the hub template is expanded, each copy
of the hub takes its input only from the appropriate bandwidth collector.
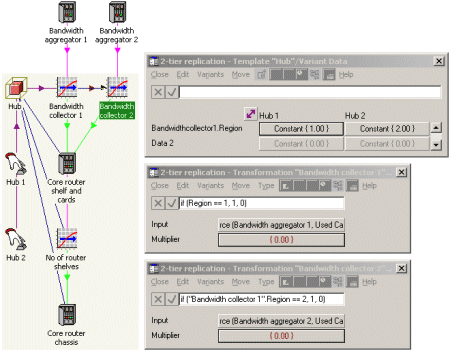
Using formulae to control multipliers for collector transformations per hub
Keeping a model manageable by design
The two-tier replication outlined here takes a little ingenuity and concentration
to set up, but requires no special or unusual functionality beyond template replication,
user data and formulae. The benefit is a concept for modelling discrete network
sites, and (by extrapolation of the same technique) any level of aggregation, which
completely avoids the risks and maintenance overhead of manually copied model blocks.